



Tips-n-tricks blog post to navigate OMSCS’s CS7641 Machine Learning (ML) course.
Important note
- I took this class in Spring of 2024, the requirements of specific assignments could have changed for the upcoming semesters.
- If you have any doubts whether the suggestions below apply to your cohort, check with the TAs, I claim no responsibility over lost marks or points.
- Use the OMSCS study slack channel
#cs7641or study groups on Discord by your cohort. 😎
Before we get into the nitty-gritties of discussing how to navigate the course, you need to get rid a couple of internal biases that can limit the derived learning.
Let’s clear the air
-
You shall reap what you sow : ML is one of those courses where the amount of work put in to understand concepts is highly correlated to the learning you shall receive. In other words, the number of training examples to achieve a low-bias low-variance mindset is high.
-
Start early : This advice is not new but it cannot be stressed enough. Each assignment comes with its unexpected challenges and it takes time for your mind to absorb and understand new information and at the same time tackle the assignment.
-
Don’t focus solely on assignments : While assignments are the main push, definitely do the lectures and read the textbook and readings. You should not end up in a scenario where you fully perform the experiments in the assignments but are not able to understand what’s going on. Plus, the book conveys good intuition on what to focus on for analysis.
Warning
The song lyrics is what you will understand if you go in blindly tuning hyperparameters without understanding the material. fhdsddhsjshjkjasaskjdihdknkamkam? 🥸
-
You’re lucky, work with what you have: I am a firm believer of keeping a positive mindset and that has helped me through the course. It is important to note that most of the libraries (sklearn, mlrose, bettermdptools) used in the course didn’t exist in the past and we’re lucky to have them. The FAQs and TA blogs are really helpful too, the past cohorts did not have them. So, let’s be a bit grateful to the TAs on improving this course for us! :)
-
Follow the assignment PDF and FAQs: An extension of the above point, follow the blogs, FAQs and assignment PDFs exclusively and you will be fine.
-
The TAs are not the enemy: The TAs are here to help. While they may make mistakes, it’s important to understand like you, they’re juggling full time jobs + a OMSCS course or two + being a TA.
-
This course will eat your time: I know that most people will not be able to cover everything here because real life. But come in with the mindset that you need to spend time in this course. Take it easy, do even simple tasks one day at a time, start early and you should be fine. Don’t compare your progress with others, just keep going. Remember, keep a positive mindset as this course calls for one to persevere and struggle.
-
Use Overleaf: Use Kyle Nakamura’s LaTeX template. It’s much easier to write reports, don’t waste time using Microsoft Word.
-
OHs are helpful: You may not be able to attend all of them and that’s okay but view the recordings or summarize the transcripts. Sometimes you find some good POVs of analysis from the OHs.
What analysis? Should I not just code the algorithms? I am a PROGRAMMER!!!
I leave it to Prof. Isbell to answer this, this will help your analysis: Charles Isbell and Michael Littman: Machine Learning and Education | Lex Fridman Podcast #148 (The links start at a specific time, watch until 14:50).
Warning
Do not steal code written specifically for the CS7641 course (eg: ChedCode), steal anything else, some egs: how to implement Decision Tree in sklearn, how to make a line/bar/scatter-plot, how to use pandas, you get the idea.
More information on analysis:
-
What is initial hypothesis? I struggled with this a lot in my first assignment. It made no sense to me what an initial hypothesis was and I have never done research papers to know what it means. Let me put it simply: looking at your data, you make an assumption on how a specific algorithm may perform then once you perform the experiment, you either accept or reject your initial assumption (hypothesis) and justify why it occurs.
-
My model has bad accuracy, I keep checking with other datasets : This is a mistake many students make, the aim of the course is not to have the best top-notch tip-top greatest model with the best accuracy. The aim is to record what you see and convey why what you see occurs. The aim of the analysis is to understand whether you have developed a deep intuition on the hyperparameters. Why changing what affects the algorithm how and how the data can be conducive or negate this effect.
Warning
THE BEST THE BEST THE BEST THE BEST??? NO , try not to go this route.
-
Grid search : On the above point, you don’t need THE BEST model so you can avoid grid search. Try to develop an intuition on how validation / learning curves show generalizability and follow the below point on scrutinizing religiously.
-
Scrutinize everything : Leave no stone unturned, scrutinize everything. Why this occurs? Could it be the formula? Could it be the data? Could it be a specific hyperparameters? Why did you make this choice? What was the intended gain with that choice and how much of that gain was achieved? The scope of “scrutinization” is up to you but don’t miss out the requirements laid out in the assignment requirements and FAQ.
-
Scrutinizing / questioning everything may feel redundant? It is not : If you feel you can convey your intuition differently, go for it. But I will tell you this, questioning everything and going to the depths in the analysis will make you a better ML engineer. I am not in tech and I may be wrong but people in this industry seem to be questioned a lot for their choices of SL algorithm / hyperparameters. Questioning everything along with initial hypothesis and justification of results seems to help indirectly with this.
-
Examples on initial hypothesis : I did not take an ML example as that may just be giving you a free hypothesis 🙃
-
Ex1: I throw a ball with an assumption (my hypothesis) that my friend will be able to catch it. However, he misses the catch (this being the experimentation) because his height was too short or my throw was too fast (the justification).
-
Ex2: Hypothesis : Let me have a coffee because it will with my productivity.
-
Experiment : Amount of work completed is checked once caffeine is taken.
-
Analysis : Statistical / ML analysis if there is huge difference with and without caffeine.
-
Conclusion : What did the analysis show?
-
Justification : Investigate on the conclusion (scrutinize everything)
-
-
Use what helps your analysis : You feel adding another image might help your justification? Do it. You feel adding a table of some information may help showcase your work better, do it.
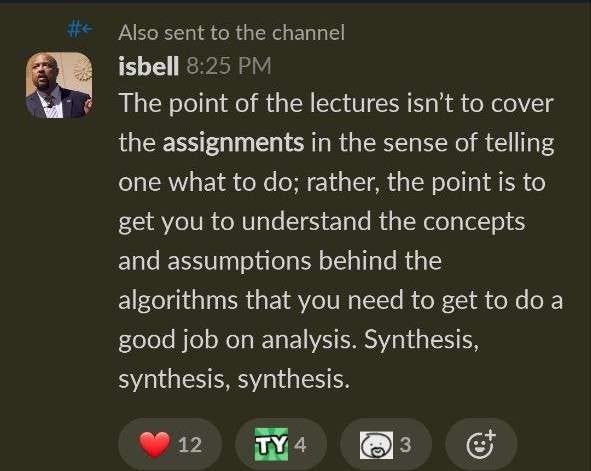
Info
This message from Prof. Isbell gives more idea on what needs to be done.
- A tip on saving time on what to talk about : Learn the concepts well and find a friend or a group of friends. Talk and discuss about your understanding and ask them to share their understanding on the topic. This will help unveil more on the subject which can be nice points in your analysis.
Assignment 1 - Supervised Learning (SL)
- Library to use : *Scikit-learn\
- For NN, if you do not want to use scikit-learn, you can also use torch or skorch as these are reusable in A2.
- A1 todo list: sl1.docx
Warning on this list
This list worked fine for Fall 2023 and Spring 2024. I’m not sure how this scales out for your current semester so don’t blame me for lost points.
- Books / Readings:
- TA blogs:TA Blogs : Supervised Learning Category
- Mitchell chapters: Ch 1, 2, 3, 4, 8
- YouTube
- StatQuest videos, 3Blue1Brown, CampusX - his videos are in Hindi but they provide good intuition on how the algorithms work, especially SVM and Boosting.
- There are many videos on Supervised Learning, explore YouTube/MIT OCW, etc.
In this assignment, you pick 2 “interesting” datasets and apply SL algorithms on them. Here are some tips.
-
What is interesting and why 2 datasets? Look at the podcast video in the above section if you have not. To summarize, you pick 2 datasets so that you can compare and contrast between the 2 datasets. You may need to try a couple of datasets before you settle on 2 which show differences. Try to pick simpler datasets, it’s not necessary to pick very complex ones and run into a situation with high run times. Also, remember that the same datasets will be use in some form and fashion in A2 and A3 so do keep that in mind when selecting.
-
Understanding for analysis : Learn how to understand and interpret validation and learning curves.
- You will later learn that the bias-variance trade-off or concepts of underfitting and overfitting is not limited to SL algorithms but can be applied to other algorithms as well if you think hard enough.
Assignment 2 - Randomized Optimizations (RO)
- Library to use: mlrose-ky lib | mlrose-ky docs
- For part 2 of this assignment where you perform weight optimization using ROs and if you used torch or skorch in A1, it is recommended to use pyperch
- YouTube:
- This playlist by Prof. Deepak Khemani, IIT Madras explains the concepts really well, the course lectures are good and in-depth.
Videos to watch
Start with the 1st video (skippable) then do 9, 10, 14, 15, 16, 17. 16 & 17 may be a little more extra information than required but do watch if it peaks your curiosity.
- Books / Readings:
- TA Blogs : Randomized Optimizations Category
- Prof Deepak Khemani has a book as well, it conveys the same intuition as the lectures that can be used to understand the algorithms
- Mitchell chapters: Ch 9 only explains Genetic algs.
- Another good book: Genetic Algorithms by David E Goldberg
- Artificial Intelligence by Russel and Norvig
- 2 papers by Prof Isbell on MIMIC
- And many more? Do message me if you have anything interesting. These are all the ones I perused in my A2 assignment.
In this assignment, you implement RHC, SA, GA, MIMIC on a problem of your choice.
- No docs : You’ve been spoilt by Scikit-learn in A1, now it’s time to torture you. The first thing you will come across is that the “hiive” version of mlrose has no documentation. Dive directly into code and understand the comments, use the docs just to understand how to create an optimization problem.
- [18.08.2024] UPDATE: You can now use mlrose-ky docs which has a nice tutorial on runners here
- Use the runners : Use the runners in mlrose-hiive/mlrose-ky, they give nice output dataframe that can be used for plotting.
- Code tip : Since the runtimes for some of these ROs can be really long (like ~12-13 hours, no joke), there are 2 ways to save your results:
- Save the output as csv and call it in another .py or notebook for plotting.
- Pickle your objects, literally saving the python objects. I prefer the above .csv route since pickling objects could take time. I didn’t try it in A2 but in A4, pickling sizes were huge.
- As always, just remember again to scrutinize everything based on assignment requirements.
Assignment 3 - Unsupervised Learning (UL)
- Library to use : Scikit-learn
- YouTube:
- StatQuest videos, 3Blue1Brown, CampusX - his videos are in Hindi but they provide good intuition on how the algorithms work, especially PCA.
- Good intuition on GMM
- Books / Readings:
- TA Blogs : Unsupervised Learning Category are very good here. Do read them throughly.
- The reading resource on ICA is helpful.
- Mitchell Ch 6, section 6.12 talks about Expectation Maximization for GMM. If you don’t know about Bayes but have the time, do understand Bayes rule.
- Selecting the number of clusters with silhouette analysis on KMeans clustering
In this assignment, you use various unsupervised learning techniques such as clustering and dimension reduction techniques alongside supervised learning algorithms. This assignment wants you to develop an intuition on:
-
Clustering : How to uncover groupings in data (clustering) when target labels are not present.
- Based on your input data, which clustering techniques are more useful? K-Means, K-Modes, GMM (any other EM technique)?
- Do the natural groupings in the data align with the actual target labels? If not, why?
- Will appending existing dataset with clustering information give your supervised learning techniques more context to work with? Can this additional context help the SL technique generalize better?
- You can look at this by different feature selection techniques as well such as decision trees, forward feature selection or backward feature selection.
-
Dimension Reduction :
- Can reducing dimensions help improve performance of supervised learning techniques?
- Do the reduced dimensions represent the same out of information as the actual dataset?
Assignment 4 - Reinforcement Learning (RL)
- Library to use : BetterMDPTools and Gymnasium
- YouTube:
- Policy and Value Iteration - an iteration of policy and value iteration, how does it look like?
- The deeplizard playlist - gives good intuition on some applications of RL that you could utilize for analysis.
- Reinforcement Learning By the Book - some people found these helpful
- Reinforcement Learning - David Silver lectures
- Books / Readings:
- TA Blogs : Reinforcement Learning Category - some code that you could utilize.
- Mitchell Ch 13 is good for Q-Learning.
- Reinforcement Learning - Sutton & Barto is a great in-depth book.
In this assignment, you model problems as Markov Decision Processes and understand how different model-based and model-free problems work on them.
- MC, MRP, MDPs : It is important to understand the difference between Markov Chain, Markov Reward Processes and Markov Decision Processes, each one of them build on each other. The David Silver videos illustrate the difference on that well.
- Value and Policy Iteration: Understand how these algorithms work. How is the policy derived in value iteration and approximated in policy iteration.
- Q-Learner : How the agent explores and exploits the space.
Congratulations!
You’re done with the assignments, wish you all the best for the Finals.

My scores
My scores were A1 (98/100), A2 (100/100), A3 (96/100), A4 (95/100) which led to an overall of 98.00 % from assignments.
I could literally skip finals and still score an A in the class, this shows the importance of giving it your all in the assignments!
In finals, I score a 32.5/57 which dropped my overall to 88.70 % leading to an A. The finals did not go so well since the questions were tricky and confusing but mostly from the lectures. Just do the lectures + George’s notes and you should be fine.
Summer scaling
Summer 2024
For the summer cohort of 2024, the course was scaled and some additions were made as below.
- A new hypothesis quiz was added to assist with better report writing at the start of the semester.
- Potentially, for summer only since timelines are short, Assignment 4 on Reinforcement Learning was dropped.
Summer 2025
The course never fails to surprise!
In summer of 2025, the course evolved yet again (yes, like Pokemons):
- 3 unit quizzes added
- A2 RO removed instead of A4.
Other interesting text to review:
- Why CS7641 is an awesome class and some tips to succeed. by suzaku18393
- A review on CS7641 ML by my classmate yxlow from the Spring 2024 cohort.
- CS 7641 Survival Guide: Strategies and Resources for OMSCS Machine Learning by Anika Neela
- Passing Machine Learning in OMSCS: Unlock the Secrets by Nexus Blogs
Changelog
- [19.04.2024] First draft completed.
- [20.05.2024] First edit.
- [09.05.2024] Second edit: added TOC, more content, updated confusing information.
- [12.08.2024] Moved to personal blog from my substack.
- [18.08.2024] Added summer cohort section.
- [18.08.2024] Added new mlrose-ky library for assignment 2.
- [30.08.2024] Added A1 to-do list.
- [15.10.2024] Updated A2 with new docs and added pyperch library
- [21.06.2025] Summer 2025 scaling